How I built a distributed and scalable IM: Zhi
Updated at: 2025-02-26
Introduction
If you don't know Zhi yet, you can read this article first. Zhi as an IM, at least the following points must be met:
- Real-time messages
- Ordered messages
- Reliable messages
- High system availability
In addition, Zhi provides zero-trust end-to-end encryption, which will not be expanded in this article. Please refer to this article and this article.
Architecture design
If it is a single-machine architecture, it is generally like this:
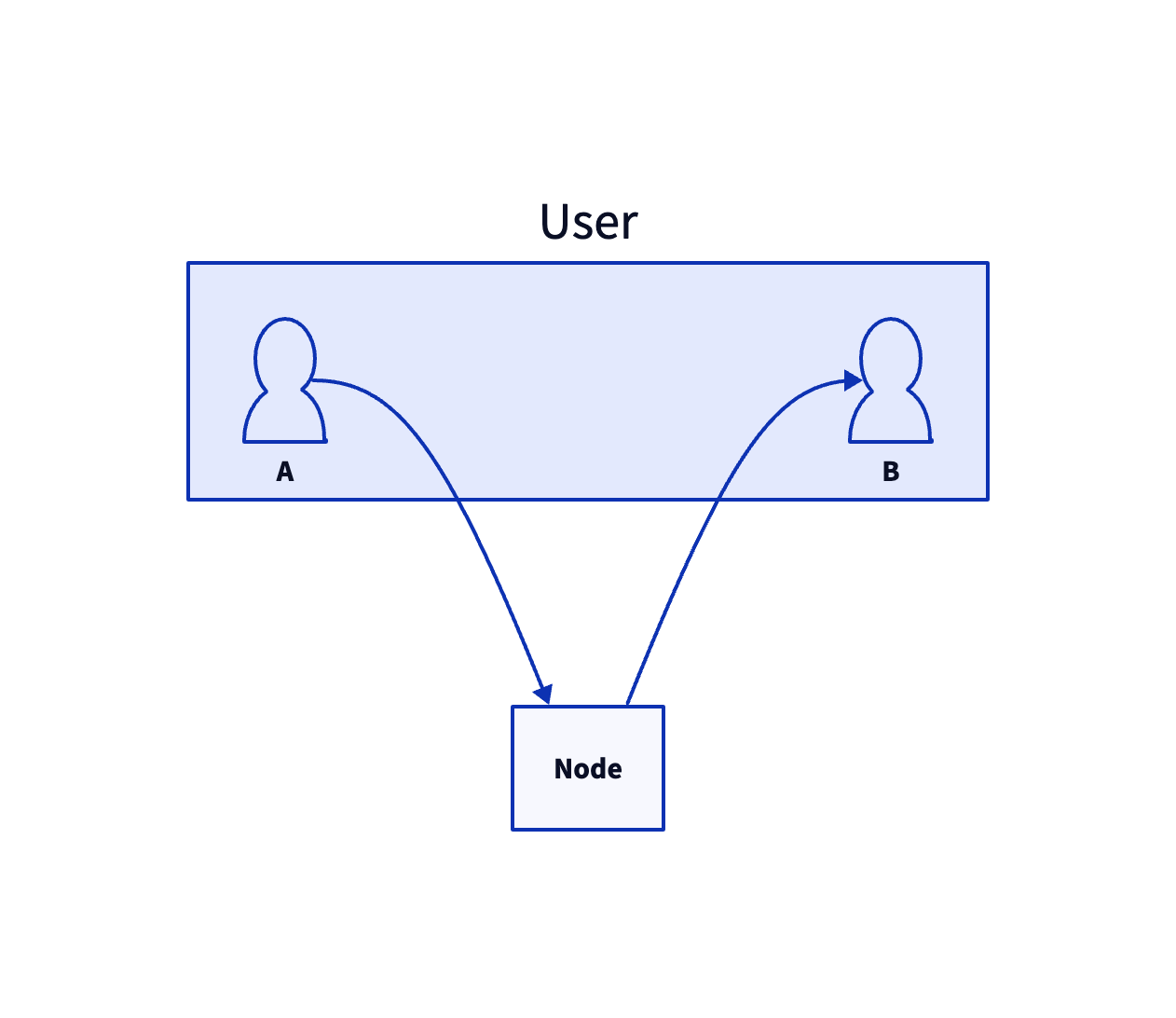
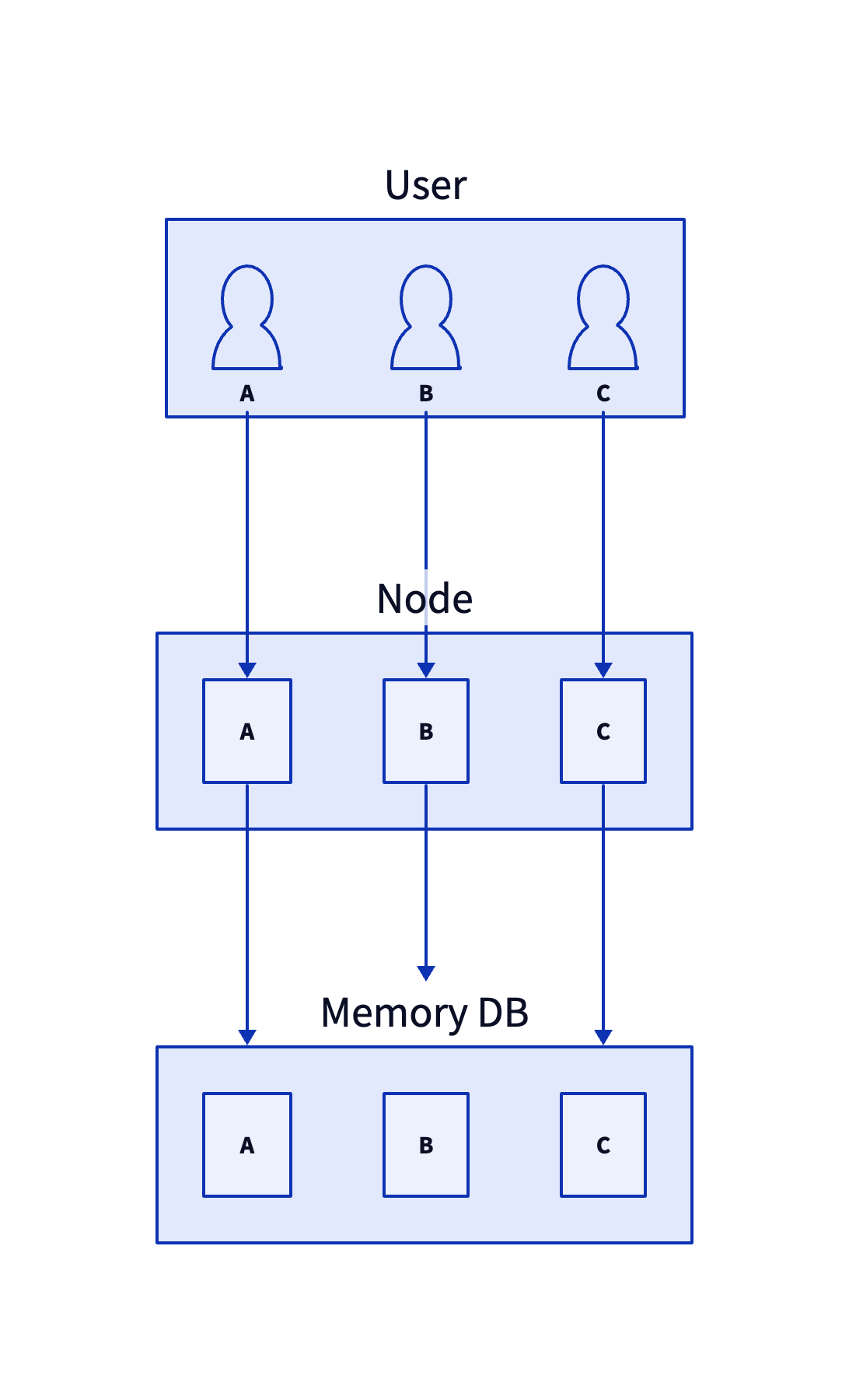
However, as the number of users increases, a single Node will eventually encounter a bottleneck. Then we need to add more nodes to evenly distribute users on different nodes. The client has a reconnection mechanism, so removing one at any time will not affect the function. Then a new problem will arise. User A wants to send a message to user B, but if they are not on the same node, then the node receiving the message needs to know which node user B is on. At this time, we introduce a Memory DB role to store the connection information of each user. Of course, Memory DB should also be a highly available cluster that can be scalable.
At the same time, a message routing role Route is introduced, which is necessary in practice and can greatly reduce the complexity of Node. That is, Node forwards the message to Route, and Route forwards the message to the required Node. Of course, Route is also a highly available cluster that can be scalable, and of course, one can be removed at any time without affecting the function.

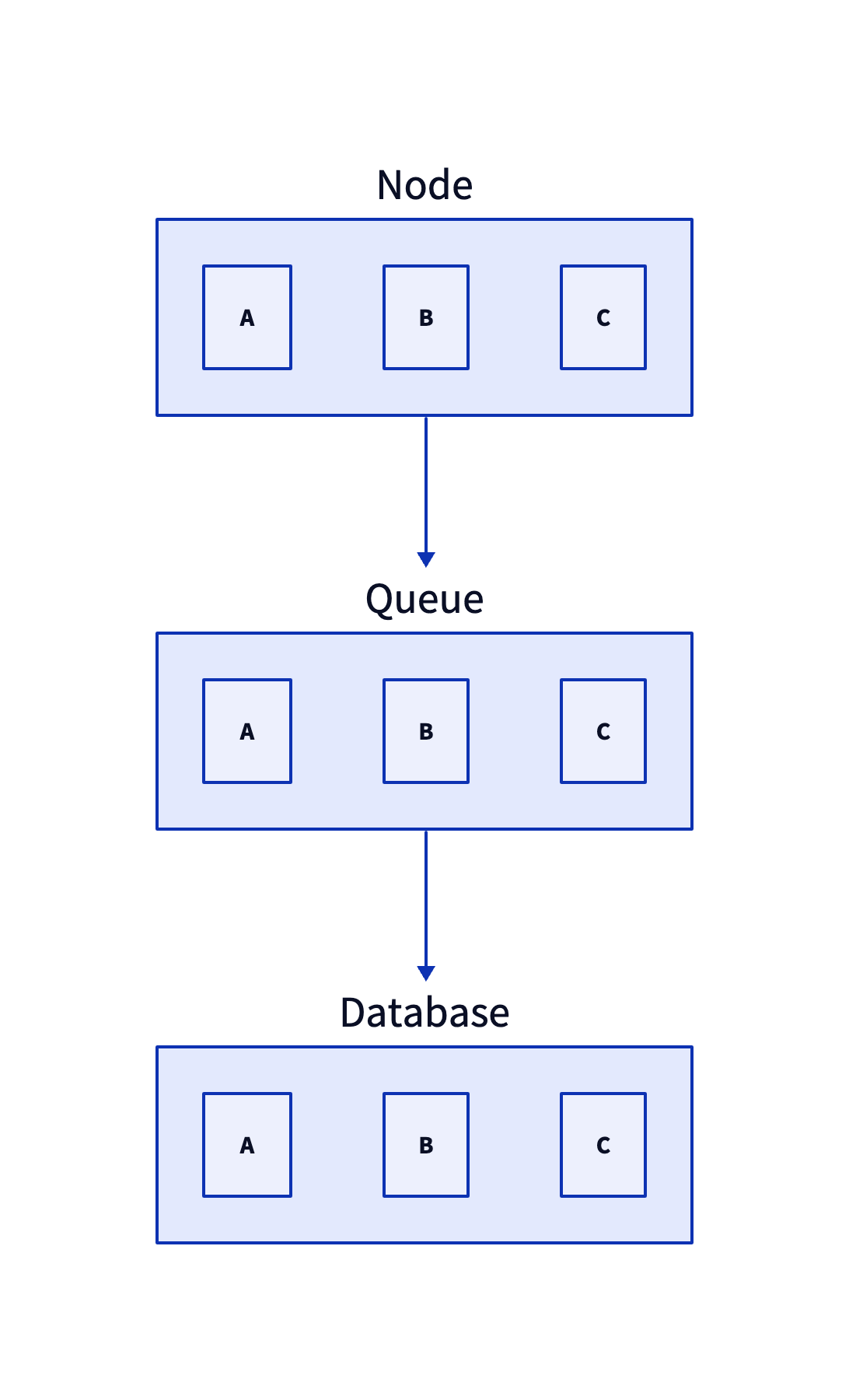
The database is the most important role and the most prone to bottlenecks. OLTP and OLAP have their own strengths and weaknesses. We choose OLTP. Of course, the database should also be a highly available cluster that can be scalable. Because of the throughput limit of OLTP, we have to introduce another Queue role, which not only makes database operations asynchronous, but also can perform many other asynchronous processing for messages. The Queue should support high throughput, reliable, scalable, and highly available clusters.
Overall architecture
The following is a brief diagram of Zhi's architecture. For the sake of clarity, I have simplified some logical relationships.
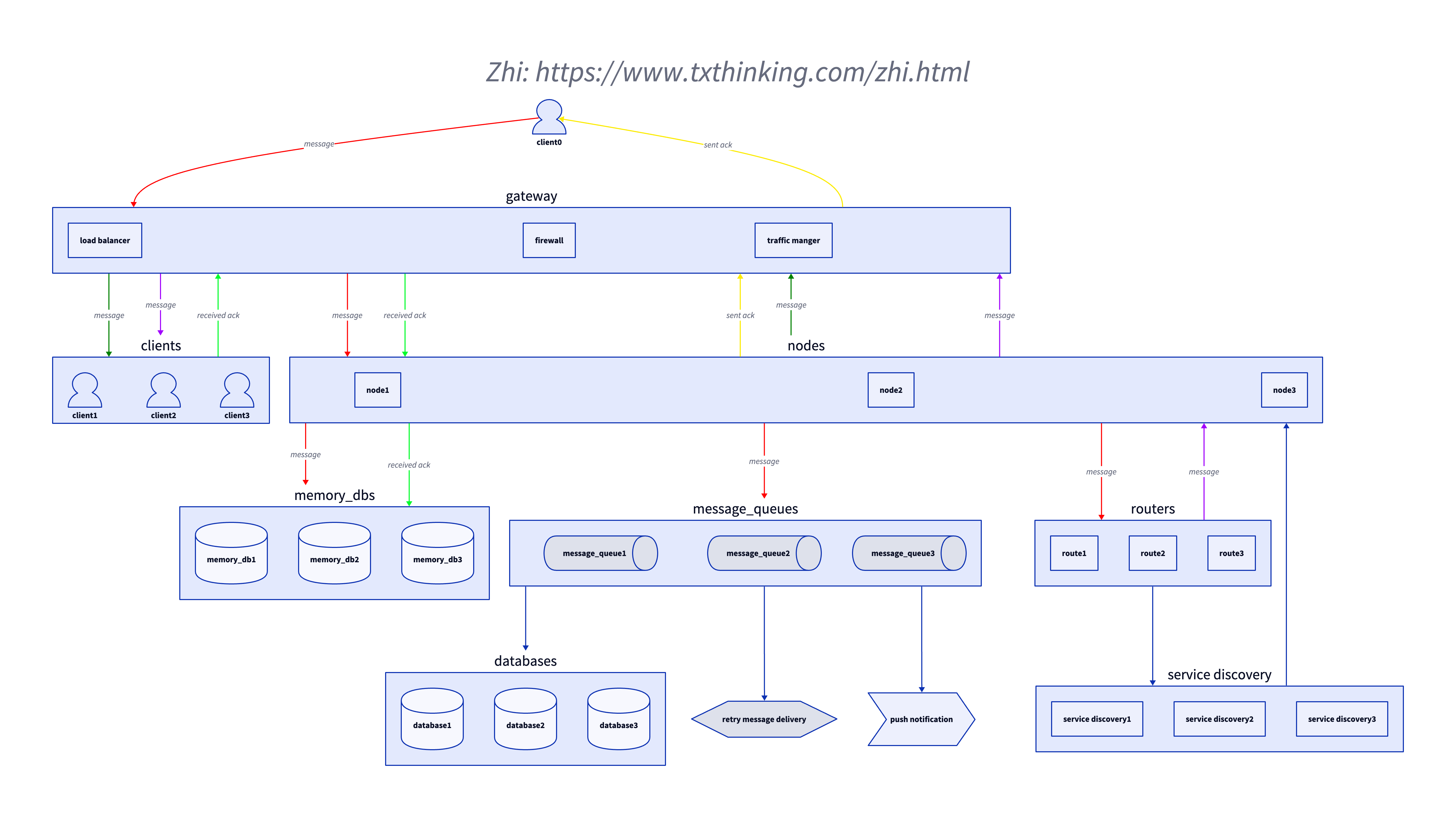
Let me talk about how Zhi, as an IM, achieves the necessary functions of an IM.
Real-time messages
The so-called implementation means that in a general network environment, the message delivery delay should be controlled in milliseconds unit. The so-called general network environment is mainly the path of the message in the Zhi system. If the user uses a snail-like network, then we cannot help the user to improve the network speed. So what we can do is to prevent the message from containing time-consuming IO operations in the path inside the Zhi system.
Transport protocol
For the network transport protocol between users and Zhi, we chose WebSocket instead of TCP because we want to treat the Web as a first-class citizen, and the impact of the header added by WebSocket on latency compared to TCP is basically negligible. Regarding the communication between the various components within the system, I would like to share some experience for reference only. Sometimes we think that choosing some popular RPC frameworks will make things simpler. In fact, it may be simpler and easier to control and ensure reliability directly on TCP or UDP based on your own specific scenarios.
Message encoding
For messages between users and Zhi, we chose JSON instead of binary because we want users to easily audit Zhi's behavior. For details, please refer to this article and this article.
Message reliability
The so-called message reliability is
- First, the user sends a message. If the user is informed that the message has been sent, then the server has indeed received it and will not lose the message due to accidents
- Secondly, the server delivers the message to the user. If the user does not explicitly inform the server that he has received the message, then the server should continue to deliver it until it considers that the user is offline
- For offline users, when they come online again, they should be able to actively pull the messages that they did not receive during the offline period
For 1 and 2, we should have two-way ACK mechanism. And for 2, we need to add a Retry role to retry the delivery of messages until the user is considered offline. For 3, we should divide messages into cold data and hot data according to some indicators and dimensions when necessary to ensure the performance of user pull.
Message storage
First, the messages sent and received by users will be stored locally to facilitate user retrieval, because the server only stores encrypted messages. It also effectively improves the performance of message list display. Only when the user is offline, the message needs to be pulled from the server after the user is online again.
Order of messages
Because when the user sends a message, the time it takes for the message to be transmitted in the network environment is unknown, that is, the time it arrives at the server is also unknown. For example, if two users send a message one after another, the first one may not arrive at the server first. Let's talk about the message time first, and then talk about the message order.
So when we show the message sending time to other users, should we show the time when the user actually sent the message? Or should we show the time when the message arrived at the server? There is actually no absolute answer to this question. Some IMs will use the time when the message reaches the server, but we choose the time when the user actually sends the message. Because Zhi is a zero-trust IM, we believe that the time of the message is also part of the message. So what if user A forges the time in a Chat and user B sees an unreal time? Let me repeat the above point. Zhi is a zero-trust IM. The user's behavior is only related to the members in the Chat. Zhi, as a zero-trust server, does not participate in the decision-making. Of course, if a member in the Chat has a Bot (Zhi supports the creation of Bots), then the forged information can be deleted, and user A can even be kicked out.
Then there is the order of messages. This involves the generation of a message ID. First of all, the message ID must be incremental, which can ensure the order of the message. Another question is whether the message ID is continuous, which determines how to deal with the message gap when the user pulls the message. If it is continuous, then the client will easily deal with the gap problem. However, in a distributed environment, to generate continuous IDs, an additional ID generator role is required, and there should be transaction guarantees when using the IDs in the future. It is quite complicated to implement this function in a distributed environment, as shown in the following figure:

If the 4th step fails, the problem will become complicated, and we also need to notify the ID generator to restore the failure. In addition, as mentioned earlier, the message time we use is the user's time. If our server uses an additional set of ordered IDs that are not related to the user's time, then the network processing time and various IO operations are not necessarily serial, and logically there may be inconsistencies with the order expected by the user.
Fortunately, the UUID standard has a new standard v7, which can be used as a distributed ordered ID with time attributes. However, this ID is not continuous, so how to deal with the message gap problem when the user pulls the message? Especially when we store messages locally on the user, when should we read messages from the local machine? And when should we pull messages from the server? Although there is a certain degree of business complexity, this can actually be done by combining the client and the server.
There is a principle here, that is, if possible, try to put complex work on the front end, because the complexity of the server increases much faster than the front end.
Finally
If you need a zero-trust IM, you might as well try Zhi. Of course, if you know programming, you can also use Zhi's Bot, which is actually a Chat member, so the messages sent and received by the Bot are also encrypted.